














































































































































Vector search emerged to fix the core flaw behind lexical keyword matching; it misses 90%+ of relevant results because of shifts in user intent, synonyms, and paraphrases.
For example, if a user searches for ‘best CRM for SaaS churn,’ a keyword-matching algorithm would stumble. It would need exact phrases containing CRM and churn to produce relevant content. Otherwise, you can expect to see lots of irrelevant results.
Vector search fixes this by mapping related concepts like ‘freemium drop-off’ to the same semantic neighborhood as the original query, providing 90% – 95% recall (i.e., results that satisfy the user’s intent, no matter how complex).
By converting text into embeddings and searching for approximate nearest neighbors (ANN), vector search delivers 90% recall in 200 milliseconds for semantic matches.
That’s why vector search embeddings live inside modern AI search stacks.
However, as we’ll explore, most models use a hybrid approach that still incorporates keyword matching to prevent semantic drift.
In this guide, we’ll trace a live query end-to-end through the stack and then reveal crucial optimizations that are essential for AI search visibility in 2026.
Converting Documents and Queries into Embeddings
 In vector search, both queries and documents are converted into embeddings, just at different times.
In vector search, both queries and documents are converted into embeddings, just at different times.
During the indexing process, documents are ingested in fixed token chunks and converted into high-dimensional numeric embeddings, which are also called vectors.
To make this conversion possible, sentence transformers, like Sentence-BERT, are required.
As implied by the name, sentence transformers ‘transform’ sentences into embeddings, which are fixed-length vectors that encode word meanings.
You can think of an embedding as an AI model’s compressed ‘understanding’ of a piece of text. The meaning behind the words is what gets measured, not the words themselves.
Due to the sheer number of dimensions involved, embeddings are dense enough that similar concepts group next to one another.
For example, ‘freemium drop-off,’ ‘reduce SaaS churn,’ and ‘best CRM for SaaS churn’ would land close together.
Content is indexed in chunk form instead of storing entire documents. This saves computation power and improves accuracy by organizing search indexes with answer-and-definition-ready snippets that an AI model can quickly retrieve later.
At query time, the user query also gets converted into embeddings and compared to its nearest ‘neighbors’ (other concepts, brands, organizations, etc.) in semantic space using a vector database.
Understanding ANN and Vector Databases
AI search indexes contain millions of embeddings, and individually comparing each query embedding to every document embedding would take eons and slow down the platform (taking several minutes to provide an answer instead of a few seconds).
Vector databases solve this problem by using special ANN indexes to quickly compute cosine similarity (and other distance metrics) between the query vector and millions of stored document vectors in under 200 milliseconds.
That’s something brute-force math can’t handle.
Here’s a very simple visualization of what graph-based vector space looks like: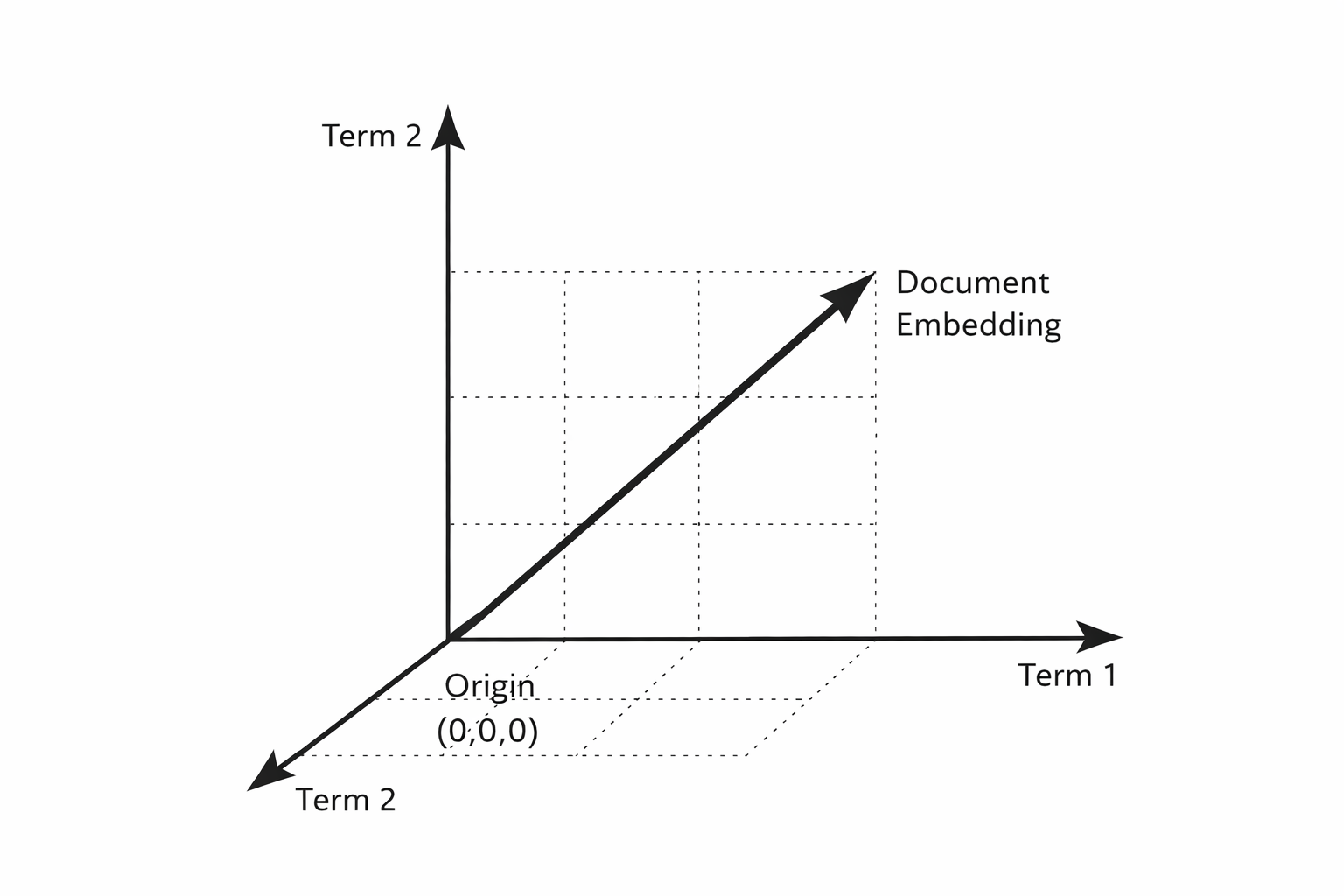
However, not all vector indexes use graphs.
The different types of vector databases
There are several types of specialized ANN indexes that provide embedding comparison, such as:
- HNSW (Hierarchical Navigable Small World): This is a multi-layer graph-based index where each embedding is a node that’s connected to its nearest neighbors. When searching for neighbors, it begins at a high-level ‘sparse’ layer that covers long distances across semantic space.
From there, it drills down to the dense lower levels to find precise connections. It’s best for high accuracy and provides fast speeds on datasets containing up to 100 million vectors. While it’s heavy on memory use, it provides excellent recall.
- FAISS-style (Facebook AI Similarity Search indexes): FAISS is more of a library of techniques than one type of index. It provides IVF, PQ, and HNSW hybrids optimized for billions of vectors through GPU acceleration and compression.
Thus, FAISS uses a mix-and-match approach to indexing, such as combining IVF and PQ for memory savings, and IVF plus HNSW for increased accuracy. FAISS-style indexes are ideal for mass scale.
- IVF (Inverted File Index): Instead of using graphs, IVF is a cluster-based index that pre-clusters embeddings into Voronoi cells. The index stores vectors by cluster ID for quick access.
At query time, the model searches for the nearest clusters and then only searches those cells. This controls breadth so that the AI model doesn’t have to jump across long distances to find approximate nearest neighbors. IVF can provide perfect recall for large datasets, and it’s easier to build than HNSW. Here’s a visualization of what an IVF index would look like: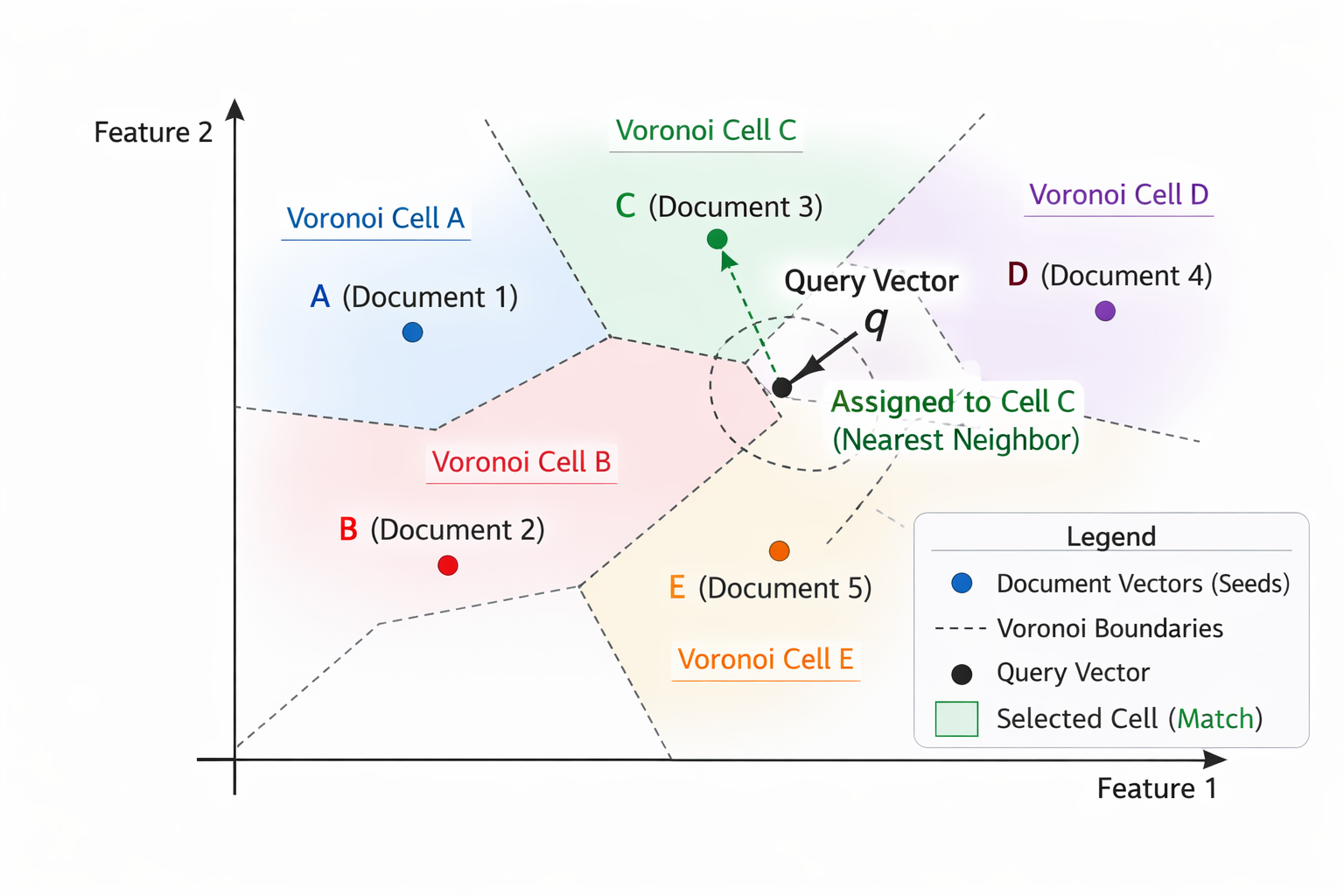
Next, let’s examine how ANN indexes do more than just provide similarity scores; they also rank candidates.
From similarity scores to ranking candidate results
ANN similarity scores serve as the ‘first pass’ ranking signal for what’s semantically relevant to the query.
Once the query moves through the ANN index, each retrieved chunk comes back with a similarity score, which is typically a value from 0 – 1 for cosine similarity. The higher the score, the closer the embedding is to the query.
Cosine similarity is index-agnostic, meaning it can work with any type of database (IVF, HNSW, FAISS, etc.). It measures the specific angle or direction between vectors, regardless of how they’re organized (graph, clusters, flat arrays, etc.).
Here’s an example.
The ‘SaaS churn’ query scores a 0.92 against a ‘freemium retention’ content chunk, meaning it’s a highly related concept. Conversely, it scores a 0.67 against generic CRM content, and a 0.23 against unrelated posts (not similar at all).
Hybrid Grounding and the Keyword Layer in AI Search

As explained in our guide covering the seven AI ranking signals, traditional keyword matching is part of the AI search stack.
Why is that?
It’s because pure vector search has the unfortunate habit of leaning into semantic drift at times, which is where it retrieves conceptually related yet irrelevant results.
The hybrid approach fixes this by mixing vector similarity with classic BM25 keyword matching.
While vector embeddings excel at paraphrases, they can overgeneralize. For instance, a vector database may match ‘customer service platforms’ with the ‘best CRM for SaaS’ query.
It’s semantically adjacent, but it’s useless for what the user actually wants to find.
Lexical keywords enforce exactness to avoid semantic drift. By including the keywords ‘CRM’ and ‘SaaS,’ generic phrases and platforms are filtered out.
That’s why AI-powered answer engines still use keyword matching as a supplementary signal to improve answer clarity, accuracy, and relevancy.
Combining embedding similarity with keyword matching is called Reciprocal Rank Fusion (RRF). It merges both ranked lists into one final set, avoiding the need to normalize different score scales:
| Scenario | Vector Score | BM25 Score | RRF Combined Score |
| “HubSpot SaaS Case Study” | 0.92 | 0.87 | #1 |
| “Customer Service Platforms” | 0.78 | 0.12 | Dropped |
| “Generic CRM Pricing” | 0.45 | 0.91 | #3 (Keyword lift) |
Notice how ‘generic CRM pricing’ gets rescued by its strong BM25 score (0.91). Pure vector search would have buried it, but the keyword filter kicked in and lifted it to #3. Also, ‘customer service platforms’ got demoted because its vector score (0.92) and BM25 score (0.12) point in opposite directions.
The term ‘HubSpot SaaS case study’ takes the cake because its vector (0.92) and BM25 score (0.87) are very similar. Both signals scream relevance, so it takes the #1 spot.
As you can see, keyword matching helps keep vector similarity scores in check, which is why AI search platforms still use it.
Turning Retrieved Chunks into AI Answers: The RAG Layer

Hybrid retrieval via ANN and keyword matching gave us the ‘top-k’ scored chunks.
What’s top-k?
It refers to the top ‘k’ vectors closely related to the prompt, which can be any value (top 10, top 100, etc.). It’s the ‘how many candidates’ knob that’s turned before answer synthesis.
K values control precision in relation to recall. A small k value will rank fast but may miss edge cases, and a large k value will be more thorough but slower.
For the purposes of this article, let’s say the ANN index returned the top 100 chunks for our ‘best CRM for SaaS churn’ query.
During the RAG (retrieval-augmented generation) layer, reranking takes place during the cross-encoder stage.
This is where trust signals like brand authority, backlinks, and third-party brand mentions enter the picture. The top-ranked chunk from ANN was “HubSpot SaaS case study.” Let’s say that after cross encoding, the chunk receives a 1.18 trust multiplier from 50+ authoritative mentions and backlinks.
Above all else, AI models look for consensus among multiple authoritative sources when determining the credibility of a chunk.
Trust signals don’t change cosine scores; they just determine which chunks make the final RAG cut.
AI models also apply E-E-A-T filters to content, looking for things like:
- Experience/expertise – Detailed author bios, bylines, and verifiable credentials
- Authoritativeness – Third-party brand citations (linked and unlinked), editorial backlinks, and user reviews
- Trustworthiness – No policy violations, HTTPS, transparency
These ensure that the model drops noise while promoting top-tier content.
Here’s the three-step hand-off involved with RAG:
- Augmentation – The LLM retrieves relevant external facts to prevent hallucinations (i.e., it pulls online content).
- Reranking – This is where the cross-encoder stage kicks in. It re-scores the chunks based on numerous trust signals (brand mentions, backlinks, author credibility, etc.).
- Synthesis – Lastly, the LLM quotes key facts, cites sources, and generates original prose to answer the user query. The ‘HubSpot case study’ chunk might become something like “HubSpot was able to reduce churn by 23% via freemium tweaks (cited source).”
By now, we’ve covered all the processes involved in interpreting and answering queries on AI search platforms.
Next, it’s time to learn how to optimize your content so that your chunks consistently make it through the pipeline and earn citations.
How to Engineer Content for the AI Search Stack

Here’s a quick review of the AI search stack that we’ve covered thus far:
- Queries and documents become embeddings
- ANN indexes retrieve top-k neighbors
- Hybrid BM25 grounds semantics and prevents drift
- RAG re-ranks and synthesizes original answers
Dominating AI-generated search results means engineering content that wins at every stage.
Chunk optimization: make each section self-contained
LLMs store content in fixed token chunks (typically no more than 400 words per chunk), and not whole pages.
That means in order to win citations, your content must be chunk-friendly.
If your blogs look like giant walls of unbroken text that contain lots of fluff and storytelling, you likely won’t earn any citations at all.
Here are quick tips for making any article chunkable:
- Split each piece into subtopics (pros and cons, FAQs, etc.) and use subheadings as boundaries (H2, H3, H4, etc.).
- Front-load your content with the most important answers and definitions (44% of ChatGPT citations come from the first third of content).
- Do not drift off topic in each section.
- Strip storytelling, fluff, and metaphors in favor of stats, quotes, processes, and lists.
Entity density: anchor your embeddings
Machine-readable authority will always beat vague prose in the world of AI search. Also, your brand needs to reinforce its entity through optimizations like:
- Adding schema markup – Schema types like HowTo, Organization, CaseStudy, and FAQPage explicitly tag your brand as the entity in question, and they help disambiguate your content.
- Ensuring NAP consistency online – Your brand’s online presence has to be consistent for LLMs to recognize you as a single, verifiable entity. Make sure your brand’s name, address, and phone number appear the same way everywhere online.
- Build consistent brand mentions – The more your brand name appears alongside related concepts, brands, and terms, the more LLMs will associate you with those ‘semantic neighborhoods.’
- Validate knowledge database entries – Ensure your brand is accurately represented in key knowledge databases like Wikidata, Crunchbase, and Wikipedia.
Entity optimization tweaks help ensure that AI search systems have a clear idea of who you are and what you do.
Trust signals: survive the reranking stage
Post-retrieval filters get rid of 70% of citation candidates, so your content has to exhibit the right signals.
Remember, raw link metrics don’t matter as much to AI search systems as they do for classic search engines. Instead of link volume and ‘building link juice,’ the goal is to establish real-world credibility through:
- Exclusive news coverage and editorial content citations (i.e., related websites choosing to link to your content, research, products, and services based on merit alone).
- Strong user reviews across multiple third-party platforms (Google, Yelp, BBB, etc.).
- Amplification through channels like Digital PR. 10 highly authoritative link placements create cross-site corroboration.
- Author expertise, such as bylines, social links, and credentials.
These signals tell AI search platforms that your brand is a verifiable, credible entity worthy of citing.
Wrapping Up: Understanding Vector Search Embeddings
Vector embeddings enable LLMs to understand the meaning behind prompts, which takes things a step further than simple keyword matching.
At the same time, old-school BM25 keyword matching remains a part of AI search to help avoid semantic drift.
The key to winning consistent AI citations is to optimize your content for every stage of the AI search stack.
Do you want to dominate the AI search results for your industry?
Book a call with our team of experts to develop the perfect GEO strategy for your needs.

